


官方文档:django-import-export
django 导出数据到excel
借助官方文档的一些数据进行理解:
class Author(models.Model):
name = models.CharField(max_length=100)
def __str__(self):
return self.name
class Category(models.Model):
name = models.CharField(max_length=100)
def __str__(self):
return self.name
class Book(models.Model):
name = models.CharField('Book name', max_length=100)
author = models.ForeignKey(Author, blank=True, null=True)
author_email = models.EmailField('Author email', max_length=75, blank=True)
imported = models.BooleanField(default=False)
published = models.DateField('Published', blank=True, null=True)
price = models.DecimalField(max_digits=10, decimal_places=2, null=True, blank=True)
categories = models.ManyToManyField(Category, blank=True)
def __str__(self):
return self.name创建导入或导出的资源
from import_export import resources
from core.models import Book
class BookResource(resources.ModelResource):
class Meta:
model = Book
# 要影响哪些模型字段将包含在导入导出的资源中,请使用fields(自定义)选项将字段列入白名单
fields = ('id', 'name', 'price',)
# 或将exclude(自定义)字段列入黑名单的选项
exclude = ('imported', )
# export_order(自定义) 选项设置导出字段的显式顺序
export_order = ('id', 'price', 'author', 'name')现在已经创建了一个模型资源,我们可以导出到csv文件
>>> from app.admin import BookResource >>> dataset = BookResource().export() >>> print(dataset.csv) id,name,author,author_email,imported,published,price,categories 2,Some book,1,,0,2012-12-05,8.85,1
定义ModelResource字段时,可以遵循模型关系,
class BookResource(resources.ModelResource):
class Meta:
model = Book
# 注意这里是中间是两个下划线,表示链式调用的模型关系
fields = ('author__name',)定义ModelResource属性时,可以遵循模型关系,
from import_export.fields import Field
class BookResource(resources.ModelResource):
''' 自定义属性时,attribute所对应的值可以是链式调用,author__name实际得到的就是作者的名字,
但是在查询时记得使用select_related(),以保证在查询时可以将所关联的外键数据一块查出,否则无法使用链式调用,
最下面会有完整的例子说明
'''
author_name = Field(attribute='author__name', column_name='作者名字')
class Meta:
model = Book
#
fields = ()
export_order = ('id', 'price', 'author', 'name','author_name')可以覆盖资源字段以更改其某些选项`
from import_export.fields import Field class BookResource(resources.ModelResource): published = Field(attribute='published', column_name='published_date') class Meta: model = Book
可以添加目标模型中不存在的其他字段
from import_export.fields import Field class BookResource(resources.ModelResource): myfield = Field(column_name='myfield',attribute='组织数据时自定义的名字') class Meta: model = Book
import_export.fields.Field可用的属性: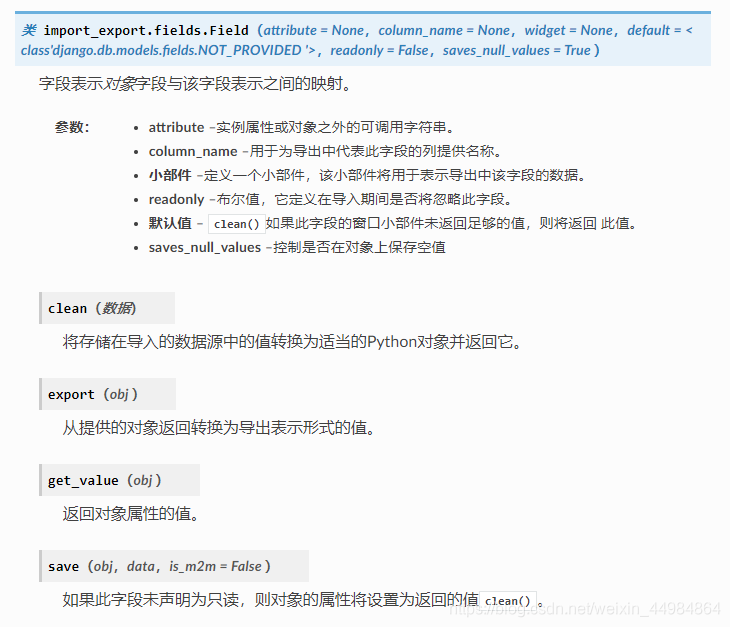
导出时进行高级数据处理:
''' 并非所有数据都可以从对象/模型属性中轻松提取。 为了在导出时将复杂的数据模型转换为(通常更简单)的已处理数据结构,dehydrate_<fieldname>应定义方法: ''' from import_export.fields import Field class BookResource(resources.ModelResource): full_title = Field() class Meta: model = Book def dehydrate_full_title(self, book): return '%s by %s' % (book.name, book.author.name)
在这种情况下,导出看起来像这样:
>>> from app.admin import BookResource >>> dataset = BookResource().export() >>> print(dataset.csv) full_title,id,name,author,author_email,imported,published,price,categories Some book by 1,2,Some book,1,,0,2012-12-05,8.85,1
自定义小部件
一个ModelResource创建与给定字段类型的默认控件的字段。如果小部件应使用不同的参数初始化,请设置widgets字典。
在此示例窗口小部件中,该published字段被覆盖以使用其他日期格式。此格式将同时用于导入和导出资源。
class BookResource(resources.ModelResource):
class Meta:
model = Book
widgets = {
'published': {'format': '%d.%m.%Y'},
}应用场景:
视图是这样的: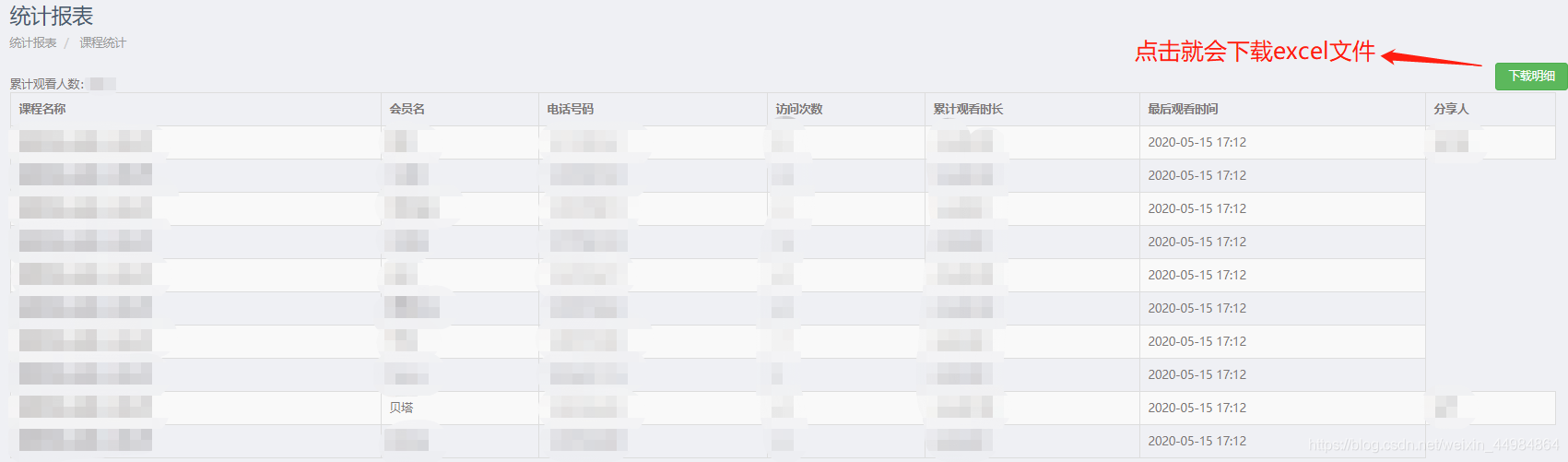
渲染上面的视图主要用到了两个表:观看表和分享表
class WatchStatistics(models.Model):
"""
观看
"""
# 支持匿名用户
user = models.ForeignKey(User, null=True)
course = models.ForeignKey(VideoInfo, related_name="watch_course")
ip = models.CharField(max_length=31)
duration = models.DecimalField(decimal_places=2, max_digits=12,
default=0.00, null=True)
createDate = models.DateTimeField(auto_now_add=True)
enterprise = models.ForeignKey(Enterprise, related_name="watch_enterprise")
startDate = models.DateTimeField()
endDate = models.DateTimeField()
type = models.CharField(max_length=50, choices=USER_TYPE_CHOICES, default=REGISTER_USER)
class DistributionRelationship(models.Model):
"""
分享
"""
# 受邀人
invited_user = models.ForeignKey(User, related_name='invited_user', null=True)
# 分享人
share_user = models.ForeignKey(User, related_name='share_user', null=True)
course = models.ForeignKey("course.VideoInfo", related_name="relationship_course")
createDate = models.DateTimeField(auto_now_add=True)
updateDate = models.DateTimeField(auto_now=True)难度就在于把两张表数据糅合在一块,并且还需要一些自定义的列,导出excel
后端代码:
from import_export import resources
from import_export import fields
from .models import WatchStatistics
class WatchStatisticsResource(resources.ModelResource):
# attribute所对应的值,中间是两个下划线,链式调用
title = fields.Field(column_name='课程名称', attribute='course__title')
user = fields.Field(column_name='用户', attribute='user__owner__name')
tel = fields.Field(column_name='电话号码', attribute='user__owner__tel')
view_count = fields.Field(column_name='访问次数', attribute='view_count')
total_duration = fields.Field(column_name='累计观看时间(分钟)', attribute='total_view_time')
endDate = fields.Field(column_name='最后观看时间', attribute='endDate')
# share_user 要对应到group_user.share_user
share_user = fields.Field(column_name='分享人', attribute='share_user')
class Meta:
model = WatchStatistics
fields = (
)
export_order = ('title', 'user', 'tel', 'view_count', 'total_duration', 'endDate', 'share_user')
widgets = {
'endDate': {'format': '%Y-%m-%d %H:%M:%S'},
}
@method_decorator(login_required, name='dispatch')
class AdminExport(View):
resource_model = None
redirect_space = None
model_class = None
datetime_fields = []
search_fields = []
default_filters = {}
prefix = ""
default_order_sort_field = ['id']
def export(self, request, queryset):
content_type = request.GET.get('content_type', 'application/vnd.ms-excel')
dataset = self.resource_model().export(queryset=queryset)
filename = "%s_%s" % (self.prefix, utils.datetime2string())
if "excel" in content_type:
suffix = "xls"
elif "csv" in content_type:
suffix = "csv"
else:
messages.error(request, u'导出格式有误!')
logger.info("export format error")
return redirect(self.redirect_space)
content = getattr(dataset, suffix)
# # content_type 这里响应对象获得了一个特殊的mime类型,告诉浏览器这是个excel文件不是html
response = HttpResponse(content, content_type=content_type)
# # 这里响应对象获得了附加的Content-Disposition协议头,它含有excel文件的名称,文件名随意,当浏览器访问它时,会以"另存为"对话框中使用它.
response['Content-Disposition'] = 'attachment; filename=%s' % (
'{}.{}'.format(filename, suffix),)
return response
class WatchStatisticsExport(AdminExport):
resource_model = WatchStatisticsResource
redirect_space = 'analysis:time'
model_class = WatchStatistics
prefix = "watchstatistics"
datetime_fields = []
search_fields = []
default_filters = {}
def get(self, request):
course_id = self.request.GET.get('course_id')
start_time = self.request.GET.get('start_time')
end_time = self.request.GET.get('end_time')
watchstatistics_list = WatchStatistics.objects.filter(course=course_id).select_related().order_by('-endDate')
if start_time:
watchstatistics_list = watchstatistics_list.filter(endDate__gte=start_time)
if end_time:
watchstatistics_list = watchstatistics_list.filter(endDate__lte=end_time)
# 查询出当前课程的分享表
distribution_list = DistributionRelationship.objects.filter(course=course_id).select_related()
invited_user_list = []
base_user = OrderedDict()
for watch in watchstatistics_list:
user = base_user.setdefault(watch.user_id, [])
user.insert(0,watch)
# 将分享表里受邀人的id所在记录append
for dis in distribution_list:
# 将拥有受邀人的id记录在列表,加入多条的话,说明同一直播,此人被不同的人邀请进来或者分享人多次访问会造成多条记录
if dis.invited_user.id == watch.user_id:
user.append(dis)
invited_user_list.append(watch.user_id)
watch_records = []
for user_id, users in base_user.items():
# 判断如果有分享的记录,则excel加入邀请人
if not invited_user_list:
group_user = users[0]
group_user.view_count = len(users)
total_view_time = sum([u.duration for u in users])
group_user.total_view_time = total_view_time
watch_records.append(group_user)
else:
# 判断如果学员与受邀人一致,则分开处理
group_user = users[0]
if group_user.user.id in invited_user_list:
# 同一个人在同一直播被多人邀请过,查找次数
num = invited_user_list.count(group_user.user.id)
# 减去分享记录和访问次数
group_user.view_count = len(users)-num
total_view_time = sum([u.duration for u in users[:-num]])
group_user.total_view_time = total_view_time
share_user = users[-1].share_user.owner.name
group_user.share_user =share_user
else:
group_user.view_count = len(users)
total_view_time = sum([u.duration for u in users])
group_user.total_view_time = total_view_time
group_user.share_user = '无'
watch_records.append(group_user)
return self.export(request, queryset=watch_records)效果如图:

评论